

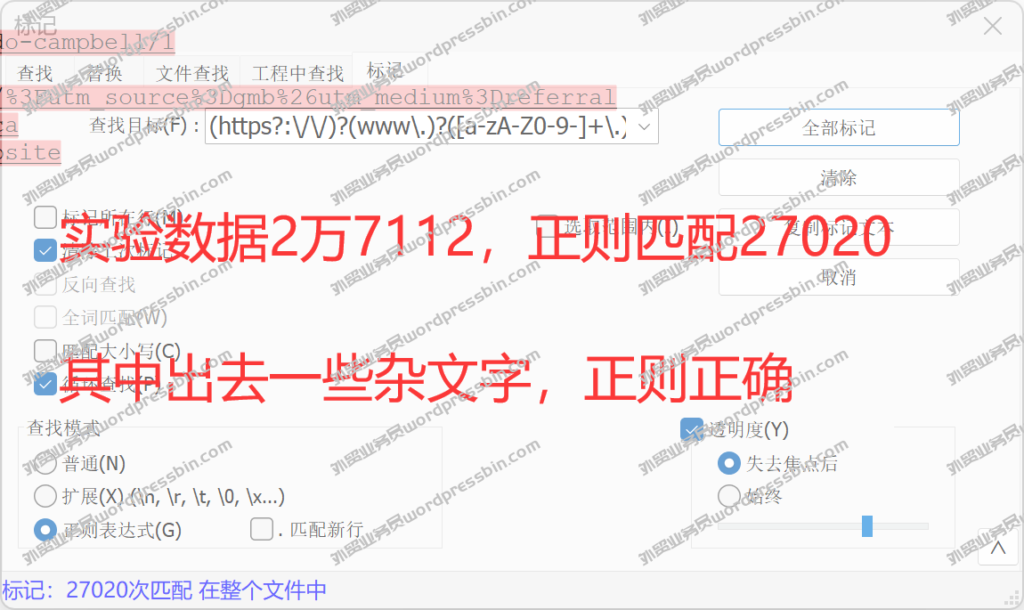


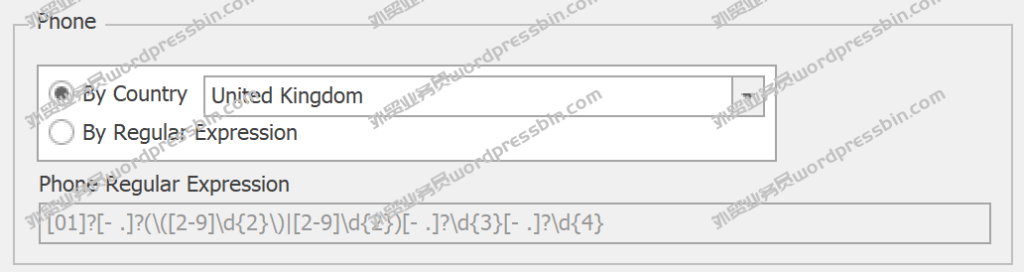
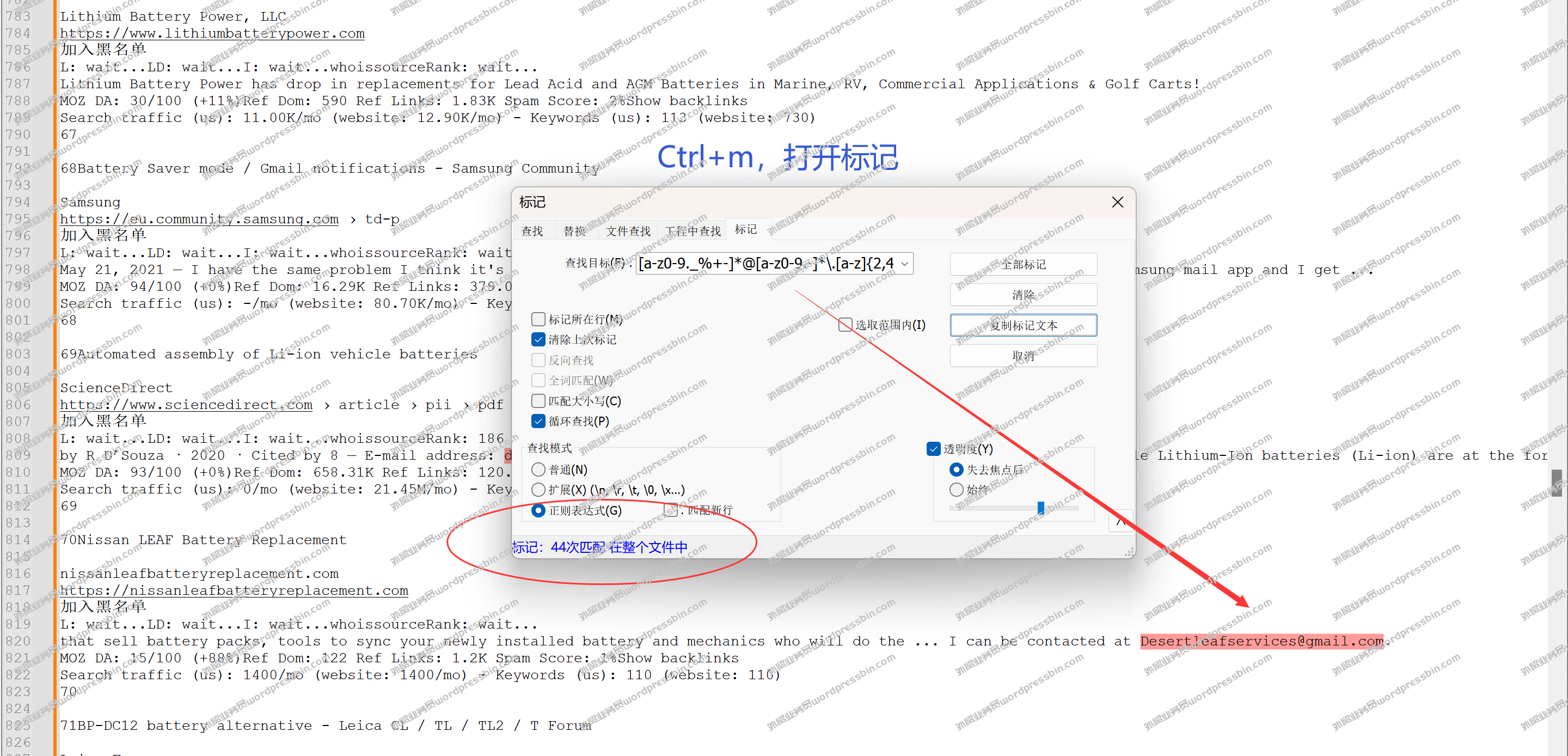





外贸客户开发工具谷歌Search All Plugin自定义搜索指令,高效2022
Search All Plug…

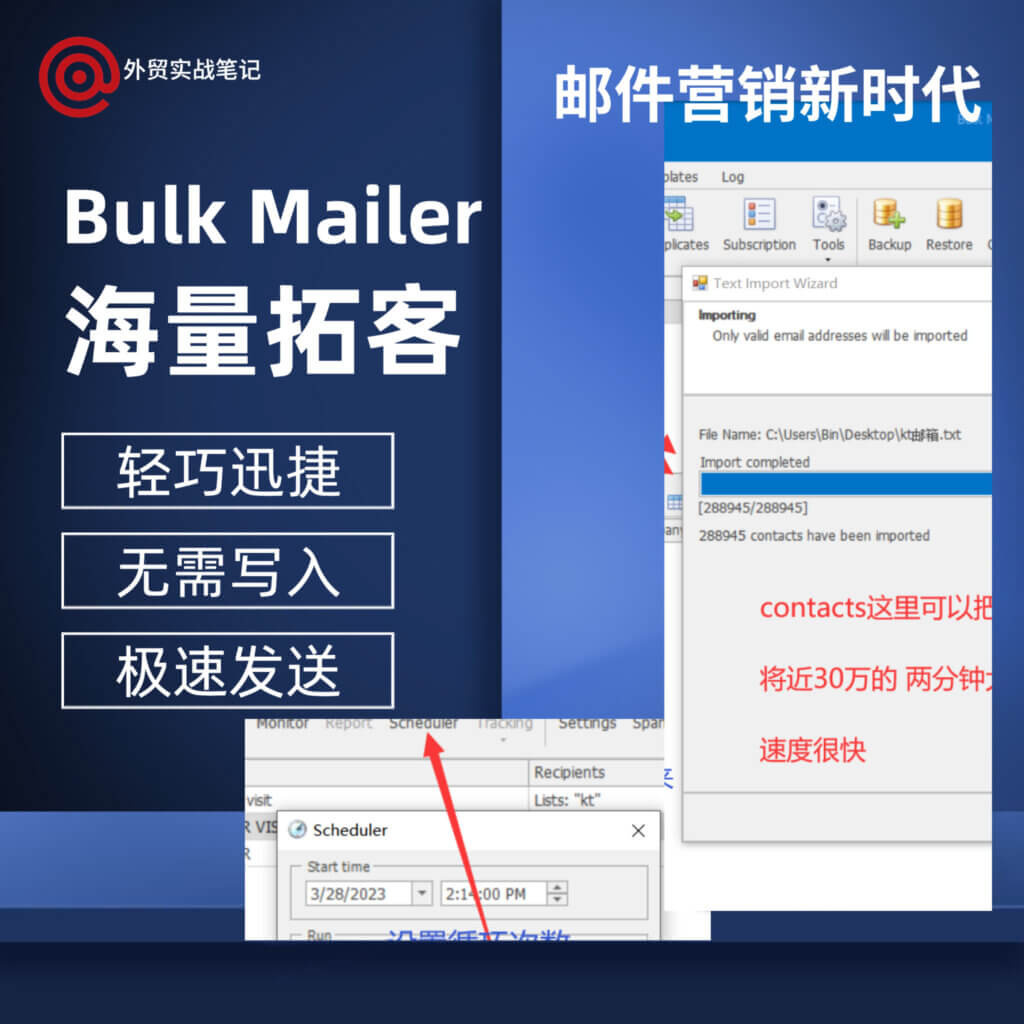
邮件群发客户端Bulk Mailer 9.5.0.4 Pro版,外贸实战笔记
邮件群发客户端Bulk Mai…
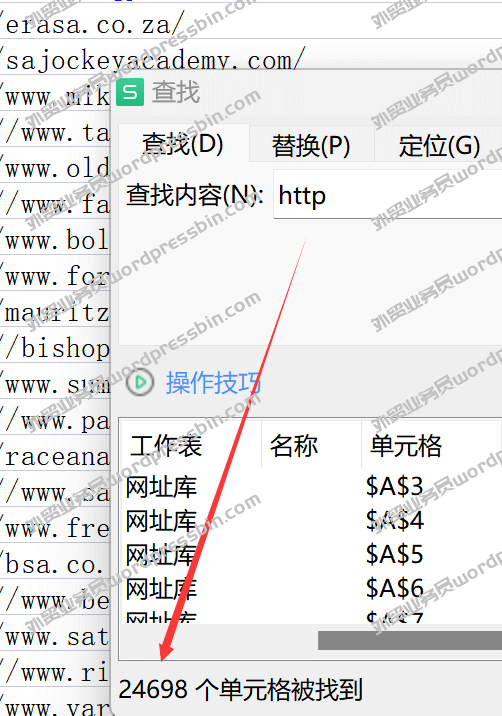
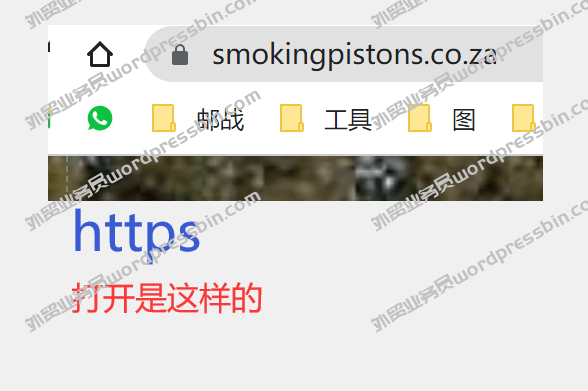
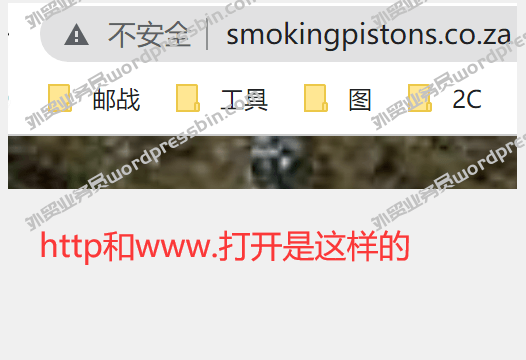
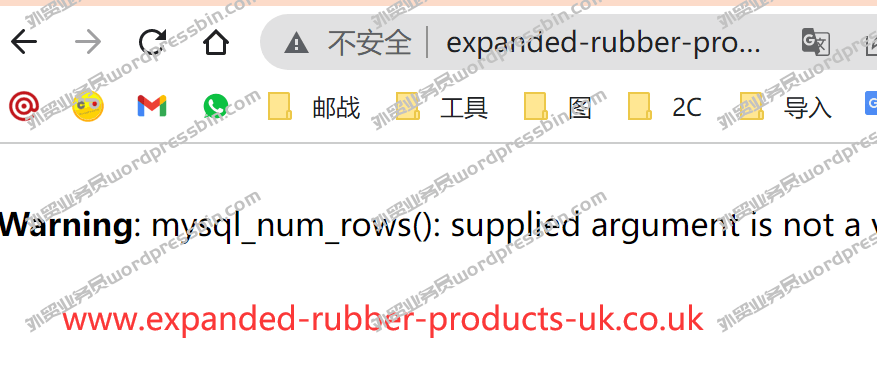
目录 前言 做英文站点的,有时…

Media Cleaner Pro外贸WordPress网站媒体库清理优化插件使用教程
目录 WP清理插件 Datab…

如何批量编辑产品PW WooCommerce Bulk Edit Pro2022
WooCommerce如何批量…

Automotive Blac…

Industrial Elec…

Industrial Elec…

Fitness Equipme…

EPDM Black Rubb…

