





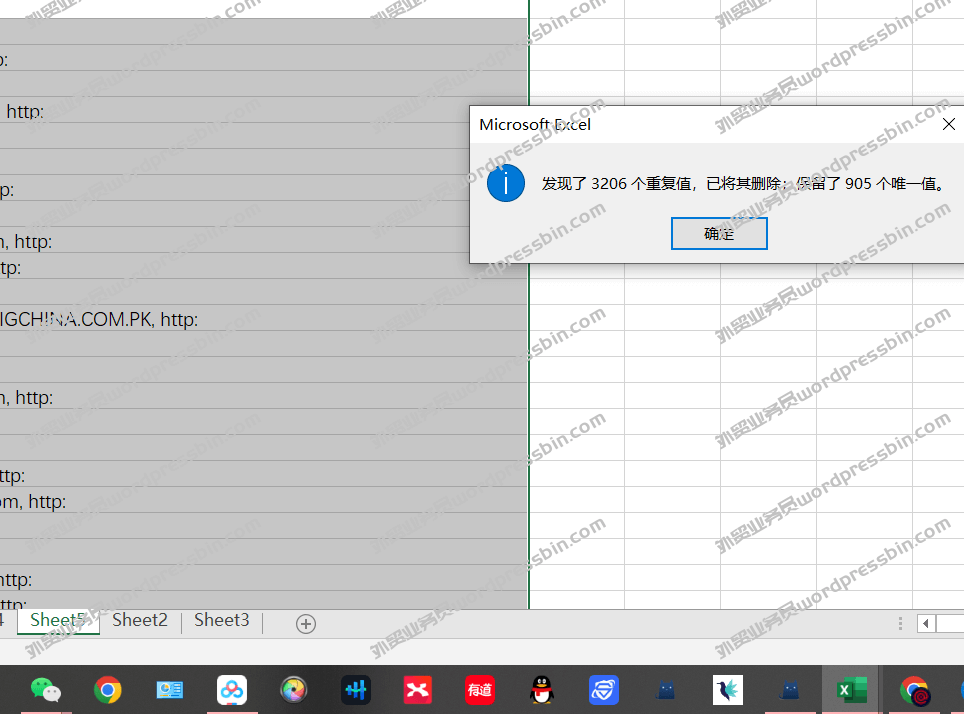
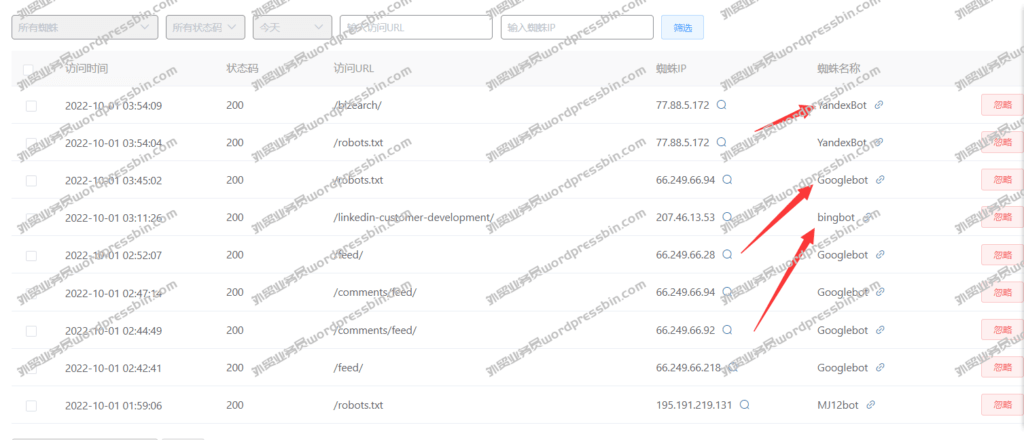
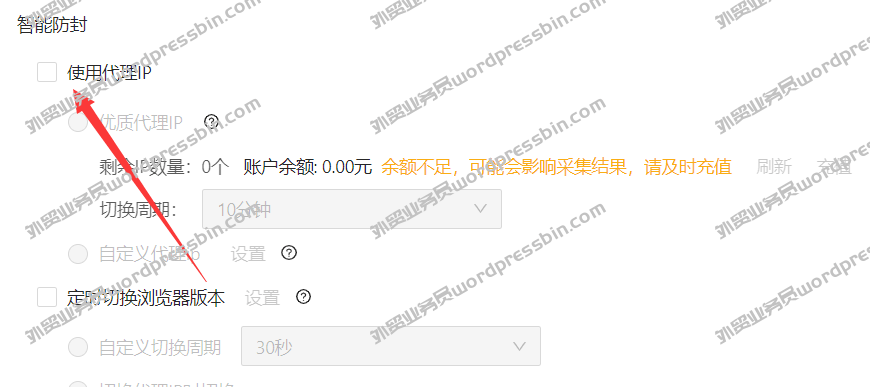




目录 前言 做英文站点的,有时…

外贸网站FAQ Schema如何设置,谷歌SEO竞争中脱颖而出
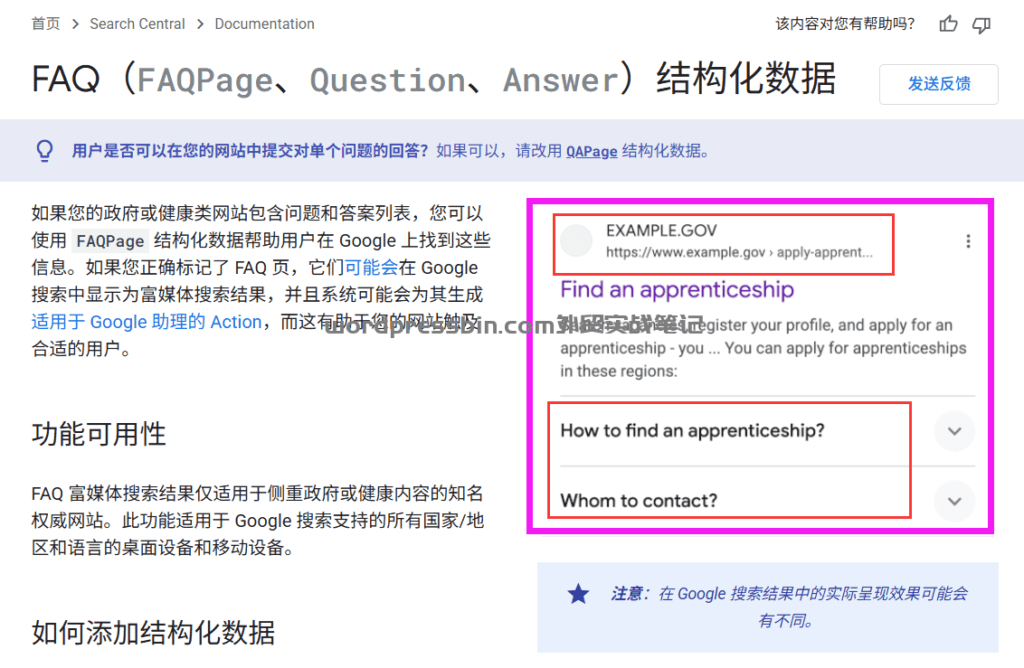
目录 前言 FAQ Schem…
如何批量编辑产品PW WooCommerce Bulk Edit Pro2022
WooCommerce如何批量…


Advanced Database Cleaner外贸网站数据库清理优化插件教程
目录 网站备份 第一步先备份,…

EPDM Car Headli…

Automotive Conn…

Racecourse Chan…

Black Rubber Au…

EPDM Rubber Foo…

