




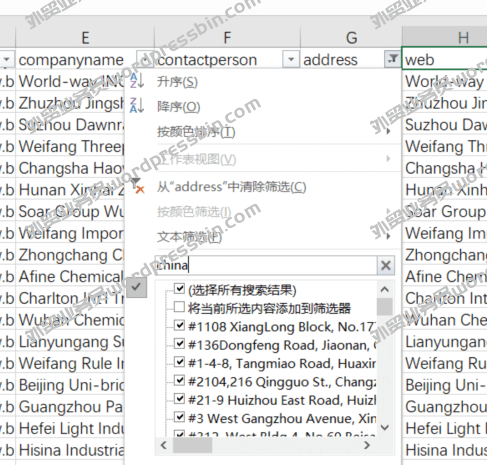
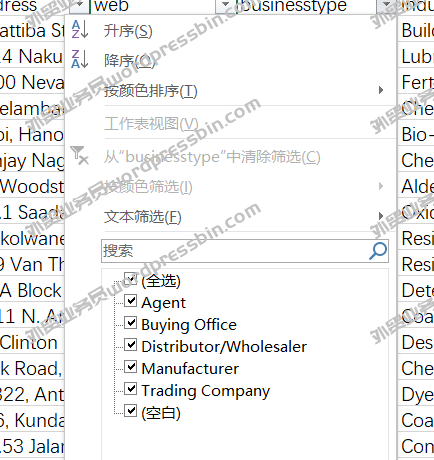

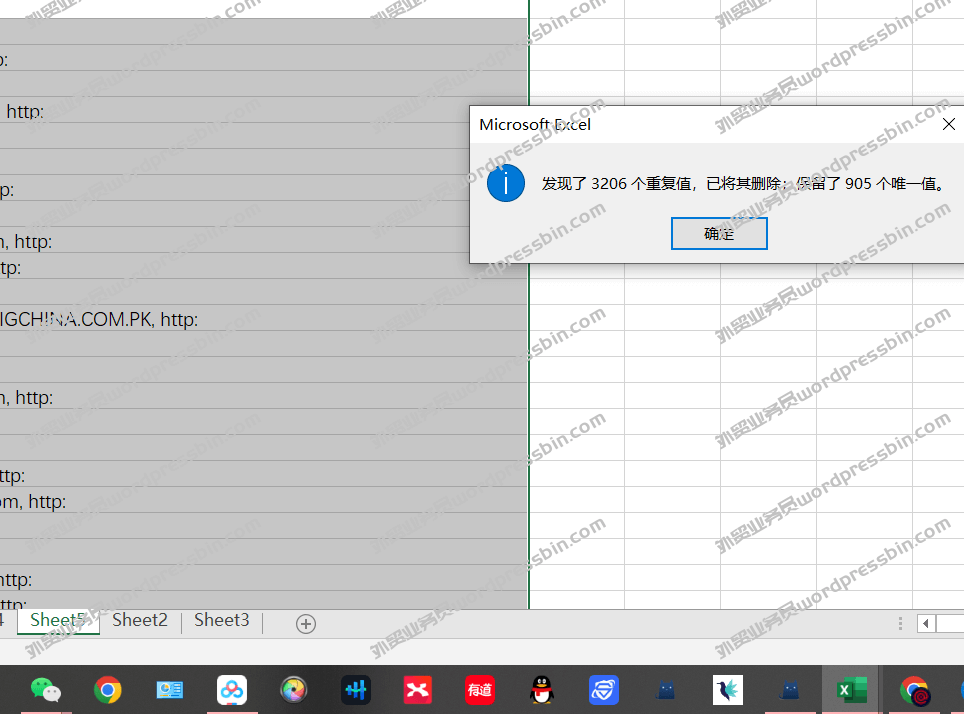
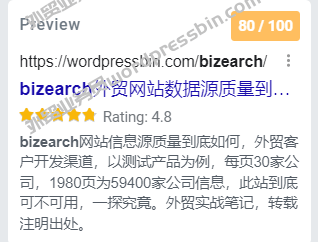
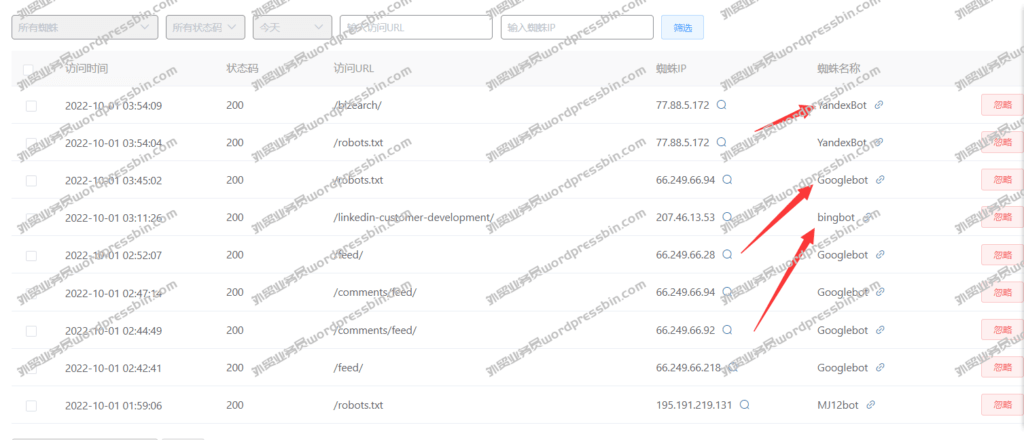
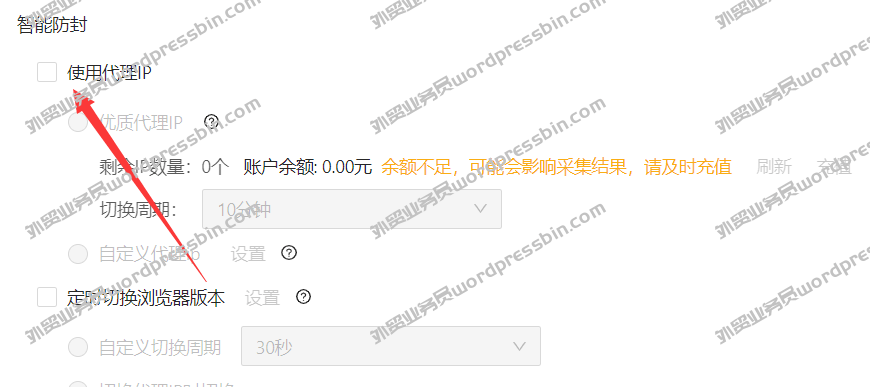





Email Extractor 7.2.1.0 Professional Cracked Version技术版,外贸实战笔记
Email Extractor…

WordPress网站询盘收不到Contact Form 7表单7邮件,Post SMTP插件设置,外贸实战笔记2022
WordPress网站询盘收不…

Payoneer派安盈无法注册,Payoneer派安盈无法提交注册链接,如何注册派安盈账户,如何注册payoneer派安盈账户,Payoneer派安盈注册教程,新手如何注册派安盈账户
Payoneer派安盈无法注册…

如何批量编辑产品PW WooCommerce Bulk Edit Pro2022
WooCommerce如何批量…

Fitness Equipme…

Automotive M6 R…

Industrial Elec…

Industrial Elec…

Automotive Lamp…

